What is RAG (Retrieval-Augmented Generation)?
How RAG works: the technology that enhances Large Language Models with updated and contextual information

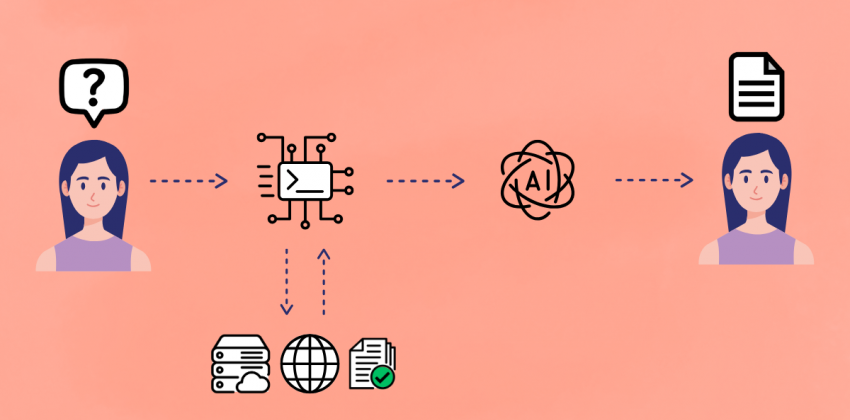
In the rapidly evolving landscape of Artificial Intelligence, Large Language Models (LLMs) have shown impressive capabilities in generating coherent and contextually relevant text. However, even the most advanced models can encounter issues such as “hallucinations” (producing plausible but incorrect information) or limitations tied to the knowledge they acquired during training.
This is where Retrieval-Augmented Generation (RAG) plays a crucial role — an innovative technique that is revolutionizing the way we interact with LLMs by making them more accurate, reliable, and up-to-date. RAG is becoming a central approach in building conversational systems, intelligent assistants, and question-answering engines that combine the power of language models with access to external knowledge sources.
In this article, we’ll explore what RAG is, how it works, why it matters, and how it differs from techniques like semantic search.
Table of Contents
- What is Retrieval-Augmented Generation (RAG)?
- How Does Retrieval-Augmented Generation Work?
- RAG and Large Language Models (LLMs)
- What’s the Difference Between Retrieval-Augmented Generation and Semantic Search?
- Why Use RAG and Why Is It So Important?
- What Are the Benefits of Retrieval-Augmented Generation?
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is a technique that enhances the ability of language models to generate accurate and informed responses by retrieving information from an external, authoritative knowledge base before generating the final output.
It essentially merges two core components of natural language processing:
- Retrieval: accessing an external knowledge base (such as documents, databases, or articles) that is relevant to a query or prompt;
- Generation: producing a coherent and contextual response using a language model (typically an LLM) fueled by the retrieved results.
Instead of relying solely on the “memorized” knowledge from its training data, RAG actively searches for relevant information from document corpora, databases, or the web and uses it as additional context to guide the LLM's output — improving its accuracy, freshness, and responsiveness.
How Does Retrieval-Augmented Generation Work?
The RAG process can be broken down into five main stages:
- Indexing – External data is converted into numerical representations (embeddings). These embeddings capture the semantic meaning of the content and are stored in vector databases optimized for similarity search.
- Query Embedding – When the user inputs a query or prompt, it is transformed into a numerical vector (embedding) using the same encoding model used for the documents.
- Document Retrieval – The query embedding is used to search the vector index for the most semantically similar documents or text fragments. This step quickly identifies the most relevant information for the user's request.
- Augmentation – The retrieved fragments are provided to the Large Language Model as additional context alongside the original user query.
- Conditioned Generation – The LLM, now enriched with specific and up-to-date information, uses both its internal knowledge and the supplied context to generate a more accurate, relevant, and hallucination-free response. At this stage, the LLM not only rephrases the retrieved information but also synthesizes, reorganizes, and adapts it into a coherent and natural reply.
RAG and Large Language Models (LLMs)
LLMs like GPT-4 or Claude are powerful in understanding natural language, summarizing, translating, and generating text, but they are limited by the training window and the number of tokens they can retain. Their knowledge is constrained to the data corpus used during training — which may be outdated or not domain-specific.
The RAG approach overcomes this limitation by:
- Allowing access to real-time information (such as news articles, internal documents, or proprietary databases) that was not part of the training data;
- Reducing hallucinations — i.e., fabricated or incorrect statements;
- Minimizing bias linked to training data;
- Enabling LLMs to answer domain-specific questions (e.g., based on a company’s internal documentation) without requiring retraining on that corpus;
- Often including references to the sources of retrieved information, enhancing trust and transparency.
In short, RAG extends an LLM’s memory and makes it a more reliable and customizable research and generation tool.
What’s the Difference Between Retrieval-Augmented Generation and Semantic Search?
Both techniques rely on the semantic retrieval of content, but they pursue different goals:
| Feature | Semantic Search | Retrieval-Augmented Generation |
|---|---|---|
| Output | List of documents or snippets | Generated response in natural language |
| Generation model | None | Present (e.g., LLMs like GPT, BART) |
| Purpose | For the user to navigate and read | Autonomous and elaborated system response |
| Customization | Limited | High: can be optimized by domain or context |
Semantic search aims to find the most relevant documents to a query based on meaning. RAG, instead, doesn’t just return results: it synthesizes and contextualizes them, offering an experience closer to a conversation with an expert.
Why Use RAG and Why Is It So Important?
The importance of Retrieval-Augmented Generation stems from three main benefits:
- Up-to-date Context
RAG enables responses based on current content without retraining the model. - Verifiable Sources
Generated content can be traced back to real, accessible documents. - Reduced Hallucinations
The external context “grounds” the LLM in reality. - Domain-Specific & Customized
RAG allows seamless integration of internal, scientific, or vertical knowledge bases. - Cost Efficiency
More affordable than fine-tuning for knowledge updates.
It’s therefore an ideal solution where precision, ongoing updates, and accountability are required.
Some potential application fields
RAG is already transforming the way we interact with AI across various sectors, for example:
- Healthcare: Assisted diagnosis retrieving from clinical research databases;
- Legal: Contract analysis based on current laws;
- Academic Research: Q&A over scientific papers;
- IT Support: Assistants that solve tech issues using internal documentation, forums, or enterprise knowledge bases.
Using RAG in Chat Applications
More and more advanced chatbot systems, such as virtual assistants in legal, medical, or customer care domains, are adopting the RAG architecture to ensure:
- Timely responses based on manuals, regulations, or recent events;
- Personalized conversations tailored to the user or business context;
- Updatable content without needing to alter the base model.
In practice, RAG transforms a generic chatbot into a specialized intelligent agent.
What Are the Benefits of Retrieval-Augmented Generation?
Here is a summary of RAG’s key advantages:
- Access to external and up-to-date knowledge
- Reduction of hallucinations typical of standalone LLMs
- Flexibility and scalability across different data sources
- Source traceability
- Greater control over response quality
- Seamless integration with existing architectures (e.g., APIs, knowledge bases)
RAG represents an evolutionary leap for LLMs, transforming them from “static encyclopedias” into dynamic systems capable of learning contextually. With its ability to blend intelligent retrieval with advanced generation, it’s poised to become a standard for both enterprise and consumer applications where accuracy and up-to-dateness are critical.
Carbon free energy for Our Cloud ![]() Low CO2
Low CO2





© 2024 Openapi SpA, a single-member company, under the direction and control of Open Holding Srl.
Viale Filippo Tommaso Marinetti 221 - 00143 Rome - Business Register: 1378273, Share Capital: €50,000.00, VAT Number: IT12485671007, Recipient Code: 'USAL8PV' - Certified Email: 
Openapi is certified in: Quality System **UNI EN ISO 9001:2015** - Data Quality **ISO 25012:2014** - Security Management **ISO/IEC 27001:2022** - Geneder Equality According UNI PdR 125:2022
All prices are net of any VAT, stamp duty, registration fees, or other taxes that may be due. All logos listed on the portal are copyrighted and owned by their respective owners.








